


在当下 AI 领域,如何高效接入多个大模型已成为技术团队必须面对的现实问题。不同模型在能力、接口以及上下文管理上各有特点,而我个人发现,像 OpenClaw 这样的工具能让整个过程变得相对轻松。本文将分享我在使用 OpenClaw 接入 Claude、GPT、Gemini 等大模型时的经验和思考,从背景优势到实际操作步骤,再到性能优化和扩展策略,力求给大家呈现一份既可操作又有思考深度的实践指南。
引言
AI大模型概述
说到 AI 大模型,你可能第一反应就是那些会写文章、画图甚至作曲的“智能伙伴”。实际上,它们背后是庞大的参数和复杂的算法。Anthropic Claude、Google Gemini 以及 OpenAI GPT 各自有着不同的训练目标和应用特点,我个人觉得这就像三位性格迥异的朋友,有的擅长逻辑推理,有的更有创造力,而有的则兼顾了两者。
这种多样性带来的好处很明显:不同场景下可以选择最合适的模型,但同时也带来挑战,比如接口差异、上下文管理、响应一致性等问题,这就是 OpenClaw 介入的空间。
OpenClaw介绍
我第一次接触 OpenClaw,是在一个需要快速切换多模型的项目中。令人惊讶的是,它不仅提供了标准 API,还允许动态切换模型而无需重启,这对于我这种喜欢快速试错的人来说非常友好。换句话说,OpenClaw 就像一座桥梁,把不同大模型的能力整合在一起,让调用变得直观可控。
而且,OpenClaw 对长上下文和多模态的支持,也让我开始思考,或许我们不再需要频繁拆分输入,模型能够“记住”更多信息,这在实际应用中省去了不少麻烦。
OpenClaw接入AI大模型的背景与优势
AI大模型的应用场景
在我的观察里,AI 大模型应用几乎无处不在。从企业内部的智能客服、文档生成,到创意产业的内容创作,再到科研领域的数据分析,几乎每个场景都能找到它的身影。尤其是那些需要自然语言理解或生成的任务,模型的能力直接影响效率和质量。
当然,这也意味着,如果没有合适的工具来统一管理这些模型,开发成本和运维成本会快速上升。我个人就碰到过一次因为模型接口差异导致整个流程卡壳的情况,那种焦虑感至今难忘。
OpenClaw在AI模型中的角色
OpenClaw 的价值在于,它不只是简单的接入工具,更像是一个协调者。我个人理解,它通过标准化接口,让不同大模型的调用方式一致,同时支持长上下文和多模态,这意味着可以在同一个会话中连续调用不同模型而不丢信息。
说到这里,我忍不住想,如果没有这样的工具,团队要么重复造轮子,要么面对碎片化的模型调用逻辑,效率低下得令人抓狂。OpenClaw 的存在,实际上为 AI 项目提供了一个统一的底座,这一点我觉得特别实用。
准备工作
环境配置与依赖
在动手之前,我通常会先梳理环境配置和依赖。说实话,这一步虽不够炫酷,但极其关键。OpenClaw 的文档中心提供了详细的配置指南,我个人的经验是:环境要尽量干净,依赖版本要匹配,这样在后续调试中就不会被莫名其妙的错误打断思路。
值得注意的是,跨平台的环境差异可能带来意想不到的问题,所以我通常会先在本地做一次完整测试,然后再部署到服务器上。
技术栈与工具选择
我个人的习惯是,选择自己熟悉的技术栈,但同时要兼顾 OpenClaw 的支持。例如,如果你倾向 Python,那么结合 OpenClaw 提供的 API 会非常顺手。另一方面,我发现一些辅助工具,比如日志管理和性能监控,也能大大降低调试成本。
说到这里,其实工具选择更多是权衡问题,你会发现有时候“越简单越好”,但又不能牺牲必要的可扩展性,这一点尤其重要。
OpenClaw接入步骤
集成流程概述
要说接入流程,我个人觉得可以用“分步推进、先小后大”来理解。首先要确认模型 API 可以访问,然后配置 OpenClaw,再测试简单请求。这个过程中,我会不断思考每一步的逻辑和潜在问题,避免盲目操作。
有意思的是,这种渐进式集成方式,不仅让问题更容易定位,也让我在学习 OpenClaw 设计理念的同时,对整个 AI 调用流程有了更直观的理解。
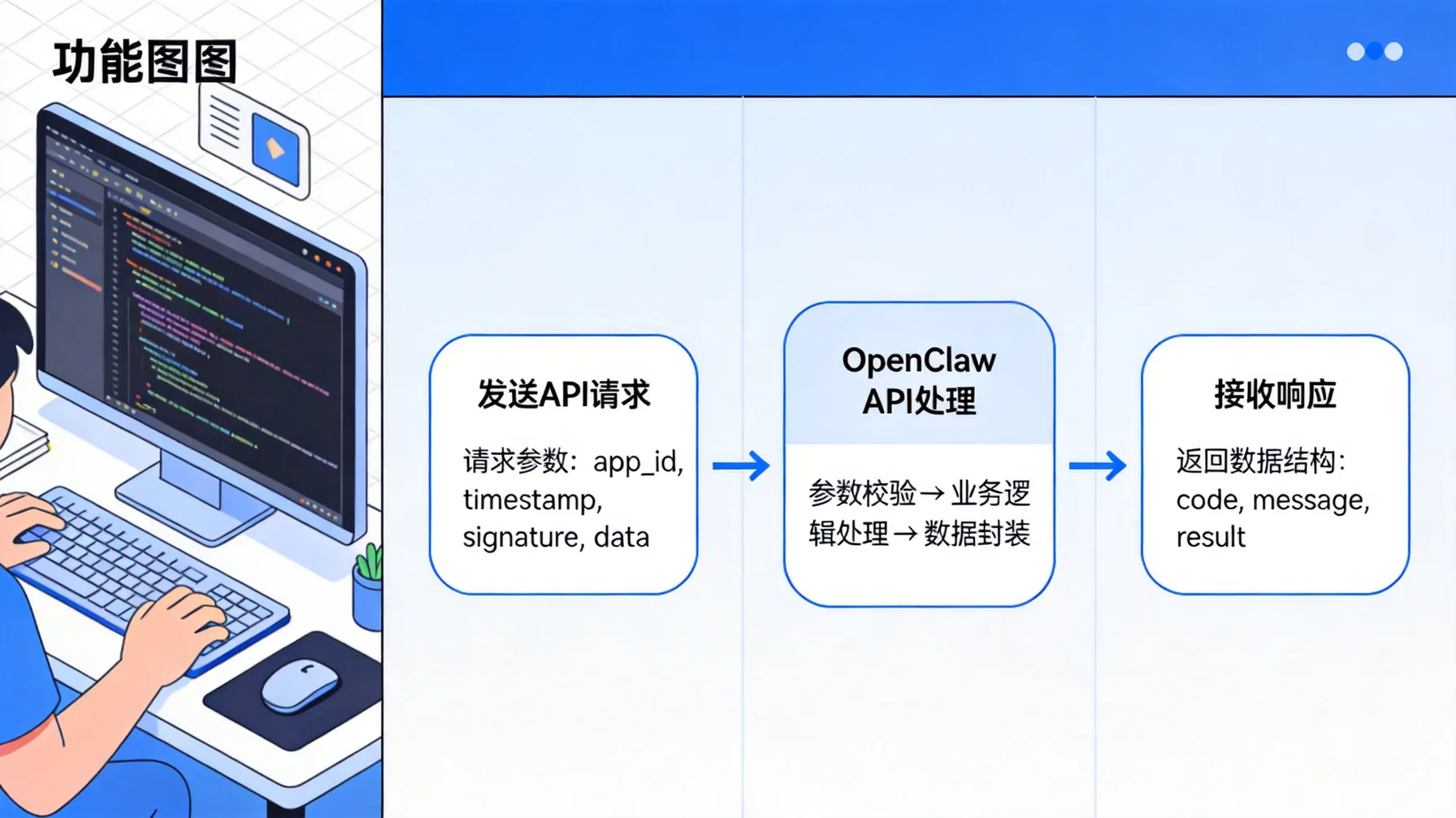
实现接口对接
接口对接其实是个挺细致的工作。OpenClaw 的 API 文档写得很清楚,但在实践中,我发现理解它的思路比死记接口参数更重要。尤其是当你需要同时接入 Claude、GPT 和 Gemini 时,接口差异和参数习惯可能让你一时摸不着头脑。
我的经验是,多跑几次请求,观察返回数据结构,然后逐步调整参数,这样才能做到既灵活又稳妥。
数据流与处理机制
在数据流管理上,我个人有个习惯,就是把处理逻辑可视化。OpenClaw 支持长上下文,这意味着信息可以连续传递,而不必每次都从零开始。这个设计让我想到了流水线作业——每个阶段都有明确的输入输出,而模型在每个阶段都可以“接住”前一步的结果。
值得注意的是,这种机制虽然方便,但也增加了内存占用和复杂度,需要在性能和准确性之间做平衡。
实践案例与最佳实践
成功案例分析
我曾参与一个内容生成项目,团队同时使用 GPT 和 Claude 来生成文本,而 Gemini 负责数据分析。通过 OpenClaw,我们实现了多模型协作,整个流程几乎没有中断。我个人觉得,这种“模型协同”的效果,既提升了效率,也让结果更加多样化和丰富。
有意思的是,通过分析日志,我们还能发现各模型的长处和短板,这对于后续优化非常有帮助。
常见问题与解决方案
说到问题,我不得不承认,初次接入时总会碰到一些坑。比如接口超时、上下文丢失、模型返回异常等。我的经验是,不要被问题吓倒,逐步拆解,定位根源,然后利用 OpenClaw 的日志和配置灵活调整。
有时候,我会把这些问题记录下来,形成团队知识库,这样每次遇到类似情况都能快速应对。
性能优化与扩展
性能监控与调整
性能优化其实是个持续过程。我个人做法是先监控响应时间和内存占用,然后针对瓶颈进行调整。OpenClaw 支持动态切换模型,这为实验提供了便利:可以尝试不同模型组合,观察性能变化。
虽然调优听起来枯燥,但看到效率提升和请求成功率增加时,那种成就感还是很明显的。
扩展性设计与部署
在扩展性方面,我个人特别注意模块化设计。OpenClaw 本身提供了跨平台支持,这意味着你可以在多个聊天工具或系统中复用接入逻辑,而无需重复开发。说到这里,其实就是在做“可复用架构”,我个人觉得这对长期项目尤其重要。
顺便提一下,部署时不要忽视监控和回滚机制,这能让扩展更安全、更可靠。
总结与展望
当前挑战与未来发展
毫无疑问,AI 大模型接入仍然存在不少挑战。包括模型间差异、上下文管理、性能优化以及多模态支持等。说实话,这些问题没有简单答案,但我个人认为,随着工具链成熟,未来会越来越方便。
值得期待的是,模型能力不断增强,而像 OpenClaw 这样的中间层工具,也在不断迭代,或许我们会迎来更智能、无缝的模型协作体验。
OpenClaw与AI大模型的协同前景
我个人比较乐观地看待 OpenClaw 与 AI 大模型的未来协作。它不仅简化了接入流程,还让多模型协作成为可能。换句话说,未来我们或许可以像调用普通 API 一样灵活地组合不同模型能力,这对于创新型项目来说,无疑是一个福音。
而且,我觉得这种协同不仅是技术层面的,更是一种思维方式的转变:如何高效利用不同智能体的长处,让系统更聪明,而不是单一依赖某一个模型,这才是未来值得探索的方向。
总体来看,OpenClaw 在接入 AI 大模型方面提供了极大的便利性和灵活性。从环境准备到接口对接,再到性能优化和多模型协作,它都展示了工具化思路的价值。通过本文的实践分享,我希望读者能够获得启发,更自信地探索多模型集成的可能性,真正将 AI 潜力转化为可落地的成果。
常见问题
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://v.siyushenqi.com/72925.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 





















{kind=link}