


在如今多模型 AI 应用越来越普遍的时代,如何高效、稳定地接入不同的模型已经成为很多开发者和技术爱好者关心的话题。OpenClaw 作为一款开源 AI 助手和代理网关,为我们提供了一个灵活的解决方案,可以通过本地部署加上第三方中转 API 实现多模型调用。本文将从 API 概述开始,深入讲解第三方中转 API 的配置方法和 AI KEY 的管理技巧,同时结合实际操作经验,分享常见问题的解决方案,帮助你更顺畅地构建自己的 AI 接入环境。
OpenClaw API 概述
什么是 OpenClaw API
我个人对 OpenClaw 的第一印象是,它并不像传统的 API 那样单纯提供数据接口,而更像一个“桥梁”,将不同 AI 模型和本地环境灵活连接起来。换句话说,如果你手里有 GPT、Claude 甚至一些本地模型,OpenClaw 能帮你把它们组织在一起,让调用变得统一且可控。
实际上,这让我想到很多开发者在多模型管理上的困扰:模型协议不统一、调用不稳定、配置复杂。而 OpenClaw 的出现,某种程度上是为了简化这些问题,让人觉得“操作没那么难”。
OpenClaw API 的主要功能
从我使用的经验来看,OpenClaw API 的功能可以概括为几个核心点。首先,它允许通过 openclaw.json 配置模型提供商,包括 OpenAI、Anthropic 等协议兼容模型。其次,你可以混合接入本地模型与云端模型,实现灵活的组合策略。
有意思的是,它还能支持第三方中转 API,这意味着你不必直接暴露每个模型的 API Key,而是通过网关统一管理调用,这在安全性和调用稳定性上都有明显优势。
第三方中转 API 配置
选择适合的第三方中转 API
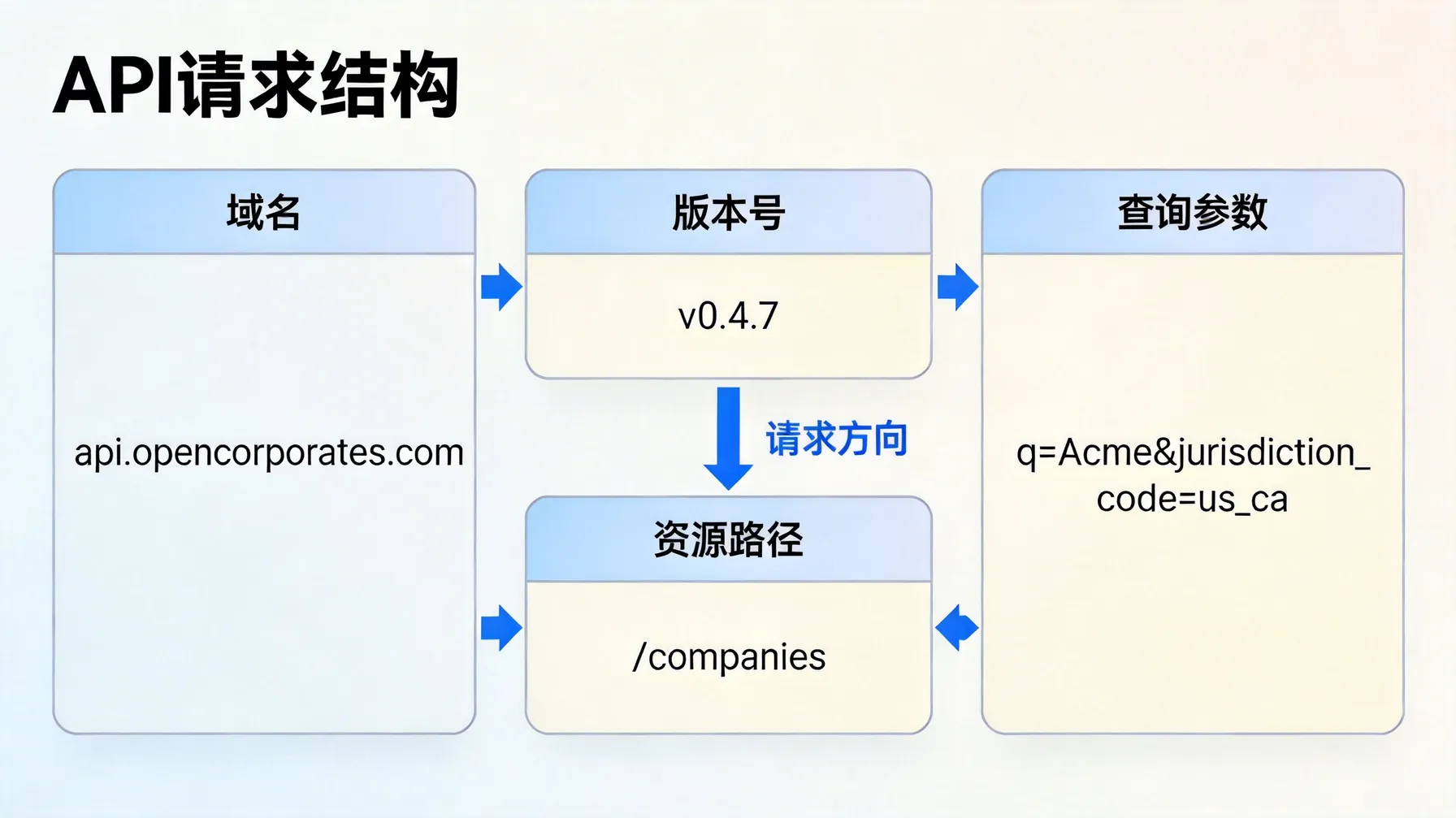
在选择中转 API 时,我自己最先关注的就是稳定性和文档完整性。要知道,如果文档写得很模糊,你就会在配置和调试上浪费大量时间。顺便提一下,不同中转 API 对接方式可能不同,有的需要额外的认证流程,有的则比较轻量,直接提供 baseUrl 和 API Key 就能用。
换句话说,选择适合的中转 API 不只是看价格或名气,更重要的是它能否顺利嵌入到你的 OpenClaw 配置里,减少调用错误和意外停机。
第三方中转 API 的接入步骤
说到实际操作,我自己最常用的流程大概是:先确认中转 API 的 baseUrl,然后获取对应的 API Key,接着在 openclaw.json 中填写相关信息,最后重启网关服务以生效。虽然步骤看起来简单,但我个人发现,很多人容易忽略最后的服务重启,这一步不做,配置不会真正生效。
值得注意的是,每次修改配置前,最好先备份旧文件,尤其是当你接入多个模型时,一个小小的错误可能会影响整个调用链。
常见问题与解决方案
在实际操作中,我遇到过最多的问题就是 API 调用失败或者返回超时。有时候是因为 API Key 写错,有时候则是网络延迟导致请求超时。这个问题没有简单的答案,需要结合具体情况去排查。我的经验是先验证 baseUrl 是否可达,再确认 Key 是否正确,最后再看日志排查异常。
虽然有点跑题,但我觉得值得提醒的是,保持详细日志和错误提示能极大节省调试时间,这一点在团队协作中尤其重要。
AI KEY 配置详解
如何获取 AI KEY
获取 AI KEY 看似简单,但实际操作中可能会碰到一些小坑。我个人的建议是直接去对应模型提供商的官方平台申请,注意选择正确的权限范围。令人惊讶的是,有些新手常常把测试环境的 Key 当作生产使用,这可能会导致调用频率受限或者调用失败。
或许可以这样理解:AI KEY 就像你的“通行证”,权限和用途一定要匹配,否则即便配置正确,调用也可能报错。
AI KEY 的配置方法
在配置层面,我的经验是尽量保持统一管理。将所有 Key 放在 openclaw.json 中对应的字段里,并确保格式正确,避免多余的空格或换行符。配置完后记得重启网关服务,让新的 Key 生效。
顺便提一下,如果你有多个模型和多个 Key,建议做好命名区分,避免混淆导致调用错误,这一点在团队项目中尤其重要。
配置过程中的注意事项
配置 AI KEY 时,我常提醒自己几件事:第一,保持 Key 的私密性,不要随意暴露;第二,确保 Key 与模型版本匹配,否则可能报错;第三,配置后做一次小范围测试,确认调用成功再上线。这个小习惯虽然简单,但能避免很多不必要的麻烦。
常见问题与解决方案
API 调用错误处理
调用 API 时遇到错误,我自己通常会按优先级排查:网络问题、Key 问题、配置问题,然后才考虑模型自身的问题。值得注意的是,有些错误提示并不直观,需要结合日志来理解。比如返回 401 或 403,基本可以直接怀疑 Key 权限;而 500 或 502 则更可能是中转服务端的问题。
我个人认为,保持耐心和系统性排查,是解决 API 错误的关键。
连接超时及解决办法
连接超时是最让人抓狂的问题之一。我通常会检查网络质量,同时确认中转 API 是否在正常运行。经验告诉我,有时候只是临时网络波动,稍等几分钟再次请求就好;但如果频繁发生,则需要考虑增加重试机制或者更换更稳定的中转 API。
总结与最佳实践
如何确保 API 配置的高效性
说到高效性,我个人总结了几条经验:保持配置文件整洁,Key 命名清晰,定期检查 API 状态,及时更新文档。虽然听起来有些琐碎,但这些小细节在长时间运维中能极大减少问题发生频率。
更重要的是,提前规划调用流程,确定哪些模型通过中转 API,哪些直接调用本地模型,这样能避免重复配置和冗余请求。
API 调用优化建议
优化调用,其实也可以从多个角度考虑。我个人倾向于几个策略:缓存常用请求结果、控制并发量、合理设置超时。还有一点往往被忽略,就是日志分析——通过日志了解调用频率、失败率,可以帮你找到性能瓶颈。
有意思的是,通过这些优化,原本感觉复杂的多模型调用,也能变得相对顺滑,就像在不同乐器之间调音一样,找到合适的节奏和顺序,一切都变得协调。
总的来说,OpenClaw 提供的第三方中转 API 与 AI KEY 配置机制,为多模型调用带来了灵活性和稳定性。通过本文的详细讲解和实践经验分享,我希望读者能在自己的项目中更加自信地搭建高效的调用环境,同时减少常见问题的困扰,让 AI 开发变得顺畅而可靠。
本文源自「私域神器」,发布者:siyushenqi.com,转载请注明出处:https://v.siyushenqi.com/72876.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 






















{kind=link}